MAUVE: Human-Machine Divergence Curves for Evaluating Open-Ended Text Generation
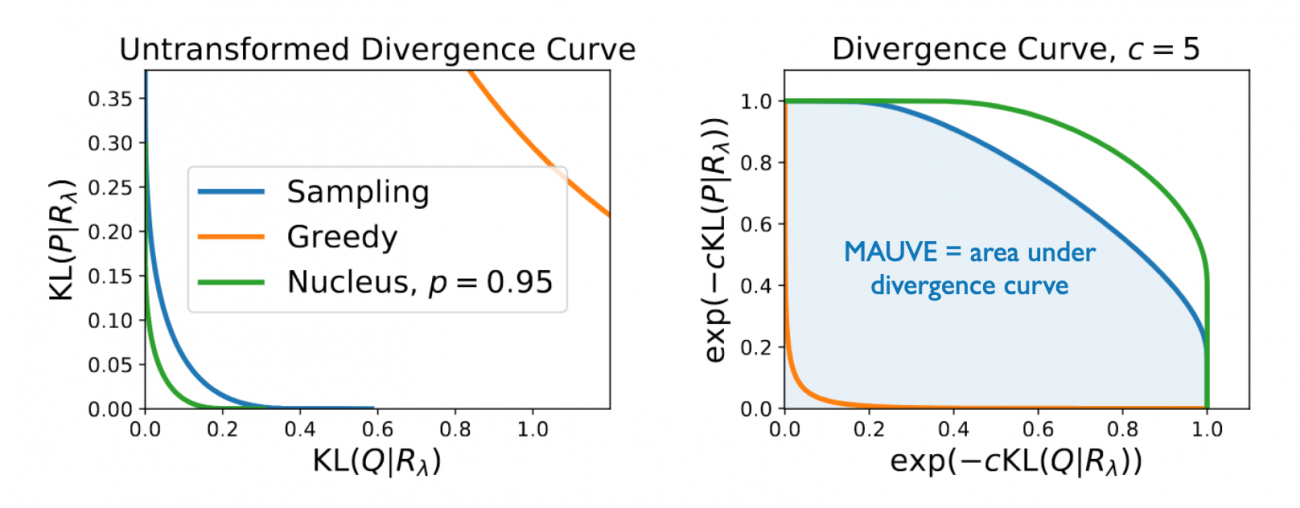
We propose MAUVE, a metric for open-ended text generation that directly compares the distribution of machine-generated text to that of human language. MAUVE measures the mean area under the divergence curve for the two distributions, exploring the trade-off between two types of errors: those arising from parts of the human distribution that the model distribution approximates well, and those it does not. We present experiments across two open-ended generation tasks in the web text domain and the news domain, and a variety of decoding algorithms and model sizes. Our results show that evaluation under MAUVE (a) reflects more natural behavior with respect to model size and decoding algorithms, and, (b) is closer to human assessment of machine-generated text, compared to prevalent metrics of open-ended text generation.
Results
We show here the Spearman rank correlation of various evaluation metrics with
- human evaluation in the webtext domain of how human-like the text is, and,
- the accuracy of a trained discriminator in the news domain.
Higher is between with a value of 1 denotes perfect agreement on all pairs, while -1 denotes full disagreement on all pairs. We see that MAUVE consistently achieves the highest correlation.
| Gen. PPL | Repetition | Sparsemax | Self-BLEU | MAUVE | |
|---|---|---|---|---|---|
| Corr. w/ human (webtext) | 0.81 | -0.17 | 0.64 | 0.60 | 0.95 |
| Corr. w/ disc. acc. (news) | 0.87 | 0.75 | - | 0.50 | 0.98 |
References
[1] Pillutla, K., Swayamdipta, S., Zellers, R., Thickstun, J., Choi, Y. and Harchaoui, Z., 2021. MAUVE: Human-Machine Divergence Curves for Evaluating Open-Ended Text Generation. arXiv preprint arXiv:2102.01454 (Bibtex)
Acknowledgments
This work was supported by NSF CCF-2019844, the DARPA MCS program through NIWC Pacific (N66001-19-2-4031), the CIFAR program “Learning in Machines and Brains”, a Qualcomm Innovation Fellowship, and faculty research awards.