Exploiting Shared Representations for Personalized Federated Learning

Exploiting Shared Representations for Personalized Federated Learning
It seems as though every few months there is a new “intelligent” device on the market that promises to make our lives easier. Smart phones, smart watches, autonomous vehicles and many more are seeking to learn from the data they collect, in order to provide greater and more effective functionality to the user, such as predicting the next word the user types or detecting pulse abnormalities that may foreshadow a heart attack.

federated machine learning systems.
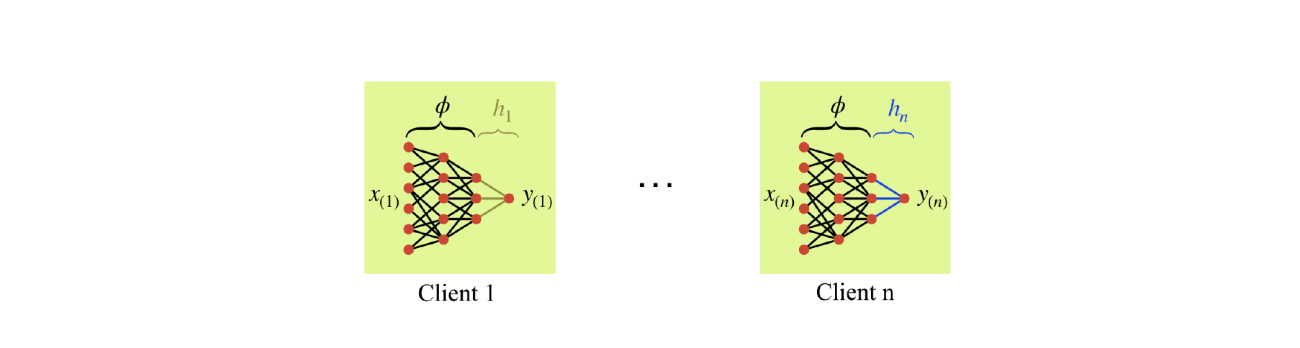
However, endowing these devices with learning capabilities presents numerous challenges compared to traditional machine learning settings. In traditional settings, models are trained on powerful servers with an extensive amount of data, but on the edge, both data and compute are relatively scarce. It is hard to fit a GPU in a smart watch! A naive approach to overcome the lack of data and compute on each device is to have every device communicate all its data with a central server. Then, the server could use its substantial computational power and the plethora of data collected across devices to train effective models. However, this is not possible in real systems because the cost of communicating all data to the server is prohibitively expensive, and the data often must be kept private, as no one is eager to share their personal data with a far-off central authority. Somehow, the central authority must learn from the data across devices to provide more effective models back to each device without access to the device data itself. Federated learning (FL) provides a means to do this. In federated learning, many devices, i.e. clients, efficiently communicate information with a central server in a manner that does not compromise the privacy of client data.Typically, this involves the server sending the clients a model, the clients updating the model based on their local data, then the clients sending their updated models back to the server. At this point, the server aggregates the models and sends the aggregated version back down to the clients to begin the next round. The most common FL algorithm is known as Federated Averaging, or FedAvg. FedAvg executes a version of the aforementioned procedure with the aggregation step being a simple averaging of the updated models. In this way, FedAvg learns a single model that is shared across clients. FedAvg allows clients to utilize a model that is trained on far more data than they possess themselves, which is very effective when the data is similar across clients. However, in realistic settings, the data across clients is often heterogeneous. In these scenarios, it may be advantageous for each client to not communicate whatsoever and instead learn using only their local data, as illustrated in Figure 2. To address this issue, we propose a personalized federated learning method that allows each client to account for the uniqueness of their local data while still leveraging the multitude of data across clients. Inspired by the observation from centralized multitask learning that data from different tasks often share the same important features, our algorithm learns a single shared low-dimensional representation that captures the relevant features for all clients. At the same time, each client learns a personalized mapping from feature space to label space that accounts for the data heterogeneity across clients. We call this approach FedRep, and visualize it in Figure 3. To analyze FedRep, we consider a setting in which each task is a linear regression problem in d dimensions and the learning model is a two-layer neural network. The representation is a matrix B that maps the data from d dimensions to k dimensions, where k is much smaller than d, and the last layer is a k-dimensional vector that outputs the prediction. We assume there exists a ground-truth representation B∗, which is advantageous for the clients to learn because knowing it would reduce the dimension of each clients’ problem from d dimensions to k dimensions, and as a result reduce the number of samples needed to solve it. We prove that FedRep learns a representation that converges exponentially quickly to the ground truth with only a factor of k2(d/n + k) samples required per client, where n is the total number of clients. Since d is much larger than k, d/n dominates the sample complexity. Meanwhile, learning locally would require a factor of d samples per client to solve each regression problem. Thus, our result reveals the benefit of collaboration to learning, as the sample complexity is reduced by a factor of the total number of clients, n.
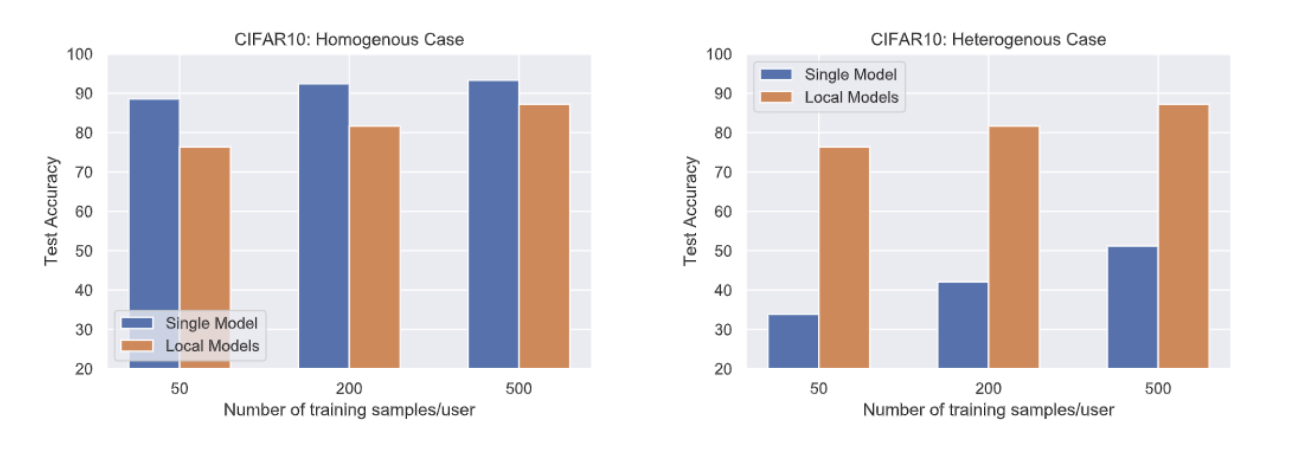
We also test FedRep via simulations of the linear setting and on multi-layer neural networks with real data from datasets including CIFAR-10, CIFAR-100 (Krizhevsky 2009), Federated EMNIST (Cohen et al. 2017) (all image classification) and Sent140 (Caldas et al. 2018) (sentiment analysis). We vary the number of clients and the level of data heterogeneity in each case. In all settings, FedRep performs the best or second-best among a variety of federated learning baselines, highlighting that exploiting shared representations can improve edge devices’ ability to learn in federated settings.
References
Sebastian Caldas, Sai Meher Karthik Duddu, Peter Wu, Tian Li, Jakub Konecny, Brendan H McMahan, Virginia Smith and Ameet Talwalkar, Leaf: A Benchmark for Federated Settings, 2018.
Gregory Cohen, Saeed Afshar, Jonathan Tapson, Andre van Shaik. EMNIST: Extending MNIST to Handwritten Letters, International Joint Conference on Neural Networks, 2017.
Liam Collins, Hamed Hassani, Aryan Mokhtari, Sanjay Shakkottai. Exploiting Shared Representations for Personalized Federated Learning, International Conference on Machine Learning, 2021.
Alex Krizhevsky. Learning Multiple Layers of Features from Tiny Images, 2009.
Image Links from Figure 1, in chronological order: https://bit.ly/3DnkOeN, https://bit.ly/3gxiQ2y, https://bit.ly/3MTiW0B.