Faster Policy Learning with Continuous-Time Gradients
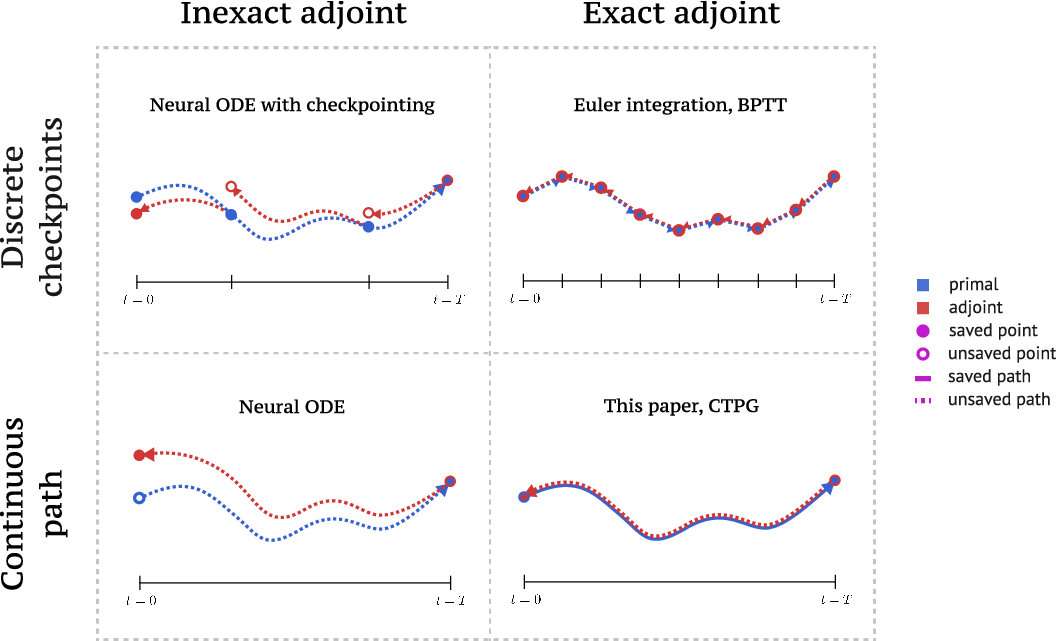
We study the estimation of policy gradients for continuous-time systems with known dynamics. The standard back-propagation through time estimator (BPTT) computes exact gradients for a crude discretization of the continuous-time system. In this work, we approximate continuous-time gradients in the original system. This perspective allows us to discretize adaptively and construct a more efficient policy gradient estimator which we call the Continuous-Time Policy Gradient (CTPG).
Empirical Results
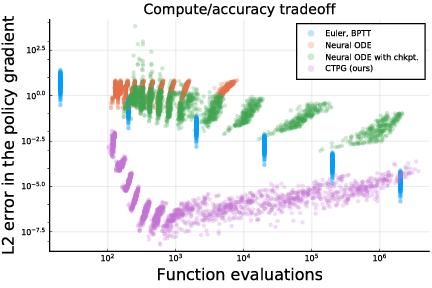
The CTPG estimator strictly improves upon BPTT, in the sense that the tradeoff curve between gradient accuracy and computational budget for CTPG Pareto-dominates the tradeoff curve for BPTT. This is illustrated below for a simple LQR dynamical system.
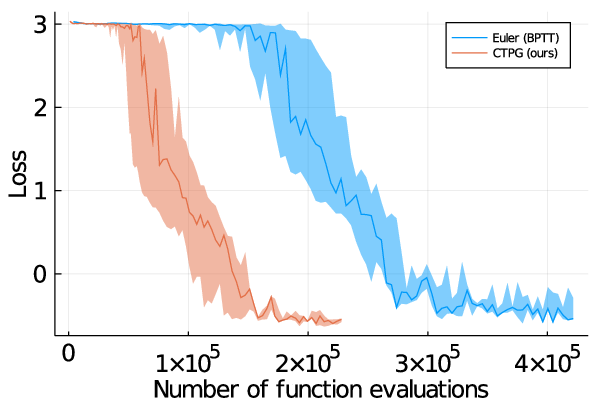
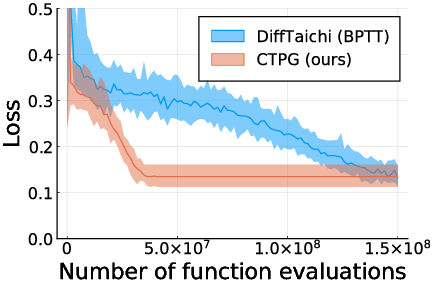
In a variety of experimental settings we demonstrate that replacing expensive BPTT estimates with relatively inexpensive CTPG estimates of comparable accuracy results in faster policy learning. This is illustrated below for the classical Cartpole system (Left) using the Mujoco simulator, and for an electric field simulation (Right) using the DiffTaichi differentiable physics simulator.
Funding Support
This work was funded by the National Science Foundation IIS (#2007011), National Science Foundation DMS (#1839371), National Science Foundation CCF (#2019844), the Office of Naval Research, US Army Research Laboratory CCDC, Amazon, Qualcomm, and Honda Research Institute USA.
References
(1) Samuel Ainsworth, Kendall Lowrey, John Thickstun, Zaid Harchaoui, Siddhartha Srinivasa. Faster Policy Learning with Continuous-Time Gradients. In L4DC 2021 [Bibtex]