Learning Winning Subnetworks Provably via Greedy Forward Optimization
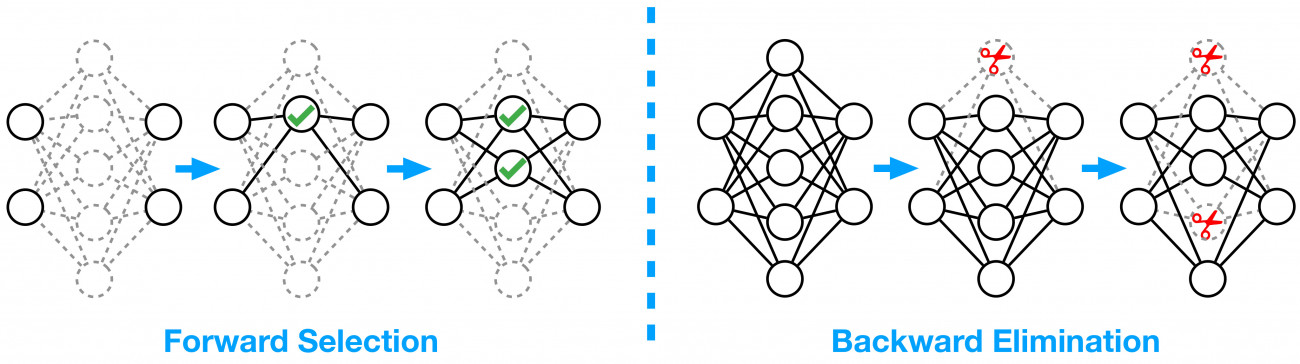
Intro
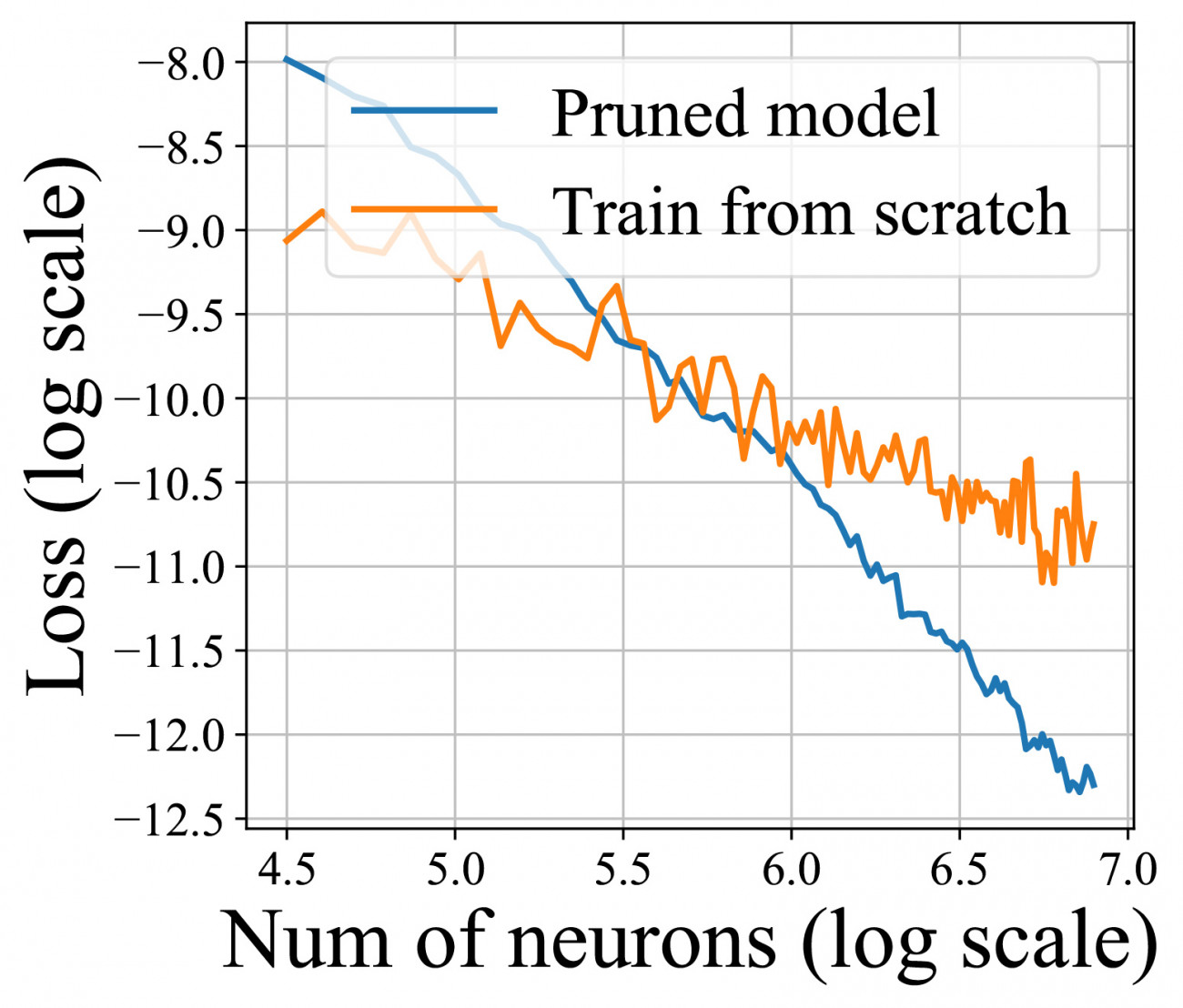
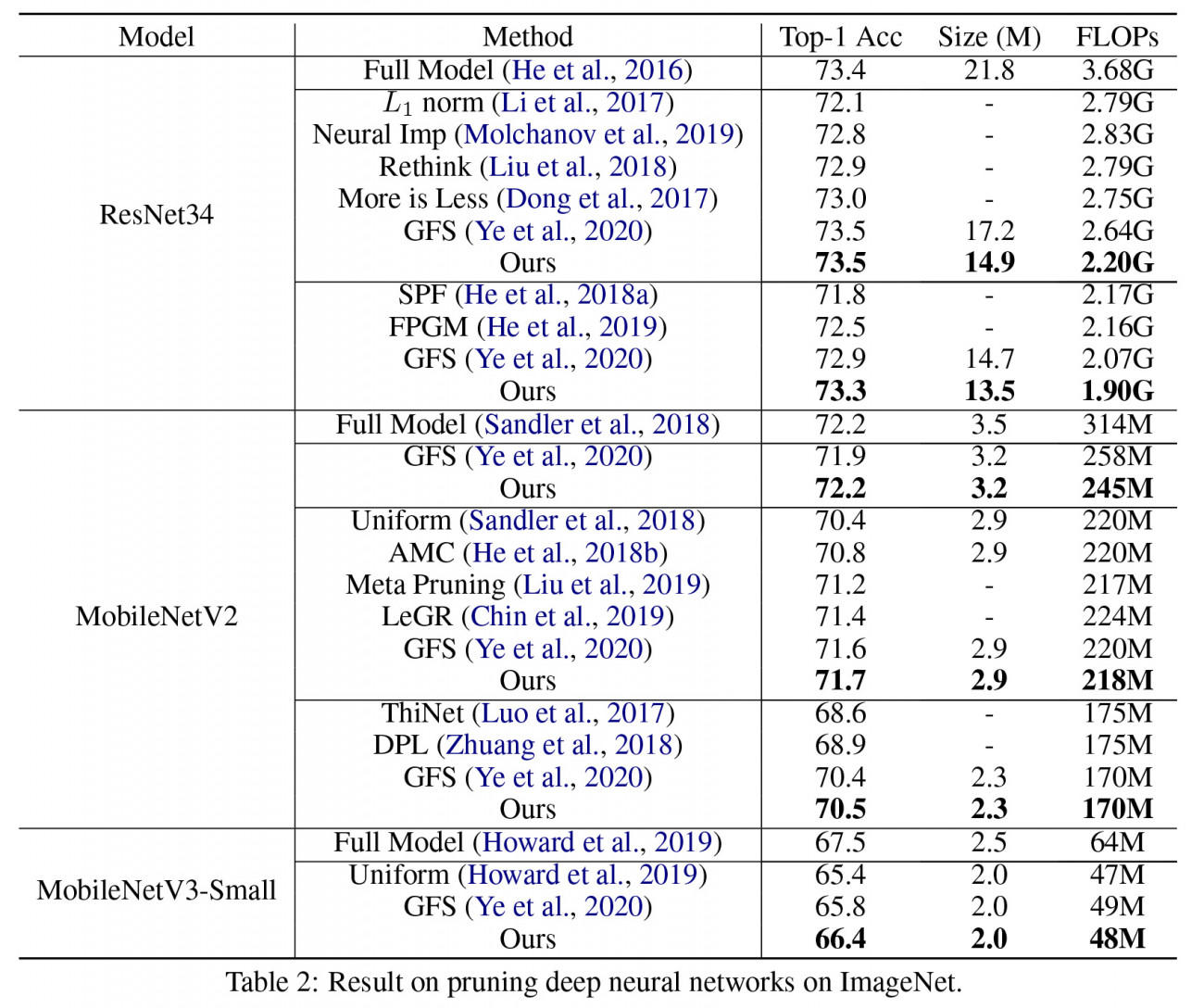
Recent empirical works show that large deep neural networks are often highly redundant and one can find much smaller subnetworks without a significant drop of accuracy. However, despite the extensive empirical successes, theoretical properties of network pruning has not been well understood, leaving a variety of open theoretical questions, including 1) whether good subnetworks provably exist, 2) how to to find them efficiently, and 3) if network pruning can be provably better than direct training using gradient descent. In recent works, we propose a provably and practical efficient greedy selection strategy for network pr which answers these questions positively. Our method finds good subnetworks starting from an empty network and greedily adds important neurons from the large network that maximize the a loss function of interest. Theoretically, we show that applying this simple greedy selection strategy on pre-trained networks guarantees to find a small subnetwork with lower loss than networks directly trained with gradient descent. Practically, we improve prior arts of network pruning on learning compact neural architectures on ImageNet, including ResNet, MobilenetV2/V3. Our theory and empirical results on MobileNet suggest that we should fine-tune the pruned subnetworks to leverage the information from the large model, instead of re-training from new random initialization as suggested by some other works.
Funding Support
NSF CAREER 1846421
Publications pertaining to the work
Mao Ye, Chengyue Gong , Lizhen Nie, Denny Zhou, Adam Klivans and Qiang Liu. Good Subnetworks Provably Exists: Pruning via Greedy Forward Selection. ICML 2020
Mao Ye , Lemeng Wu and Qiang Liu. Greedy Optimization Provably Wins the Lottery: Logarithmic Number of Winning Tickets is Enough. NeurIPS 2020