Multitasking Models are Robust to Structural Failure: A Neural Model for Bilingual Cognitive Reserve
Research thrust(s): Advanced Algorithms for Deep Learning

Evidence from cognitive science indicates that bilingualism increases human brain robustness by reducing the rate of aging cognitive decline and delaying dementia. It appears that individuals who speak more than one language on a regular basis are able to maintain typical cognitive functioning despite neural degeneration. This robustness in cognitive functioning despite brain pathology is called cognitive reserve, and its underlying mechanisms are poorly understood.
Inspired by this research, we study whether artificial neural networks are more robust when trained on multiple languages or multiple tasks. Our experiments demonstrate that training on multiple tasks indeed increases structural robustness.
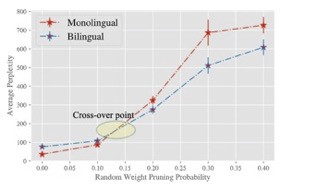
We train monolingual and bilingual GPT-2 models with the same architecture and dataset sizes. Initially, monolingual GPT-2 models are slightly outperforming the bilingual ones, but when we introduce structural noise (by randomly deleting neurons or adding noise to the weights) bilingual models degrade more gracefully and eventually outperform the monolingual models in the high-noise regime. For some amount of noise, bilingual models start outperforming the monolingual ones demonstrating a cross-over in performance due to their increased robustness. We observe this phenomenon for numerous models across three different types of corruption: Additive Gaussian noise to the weights, random weight pruning and magnitude-based weight pruning.
We provide a theoretical justification of this robustness by mathematically analyzing linear representation learning and showing that multitasking creates more robust representations. Our analysis connects robustness to spectral properties of the learned representation and proves that multitasking leads to higher robustness for diverse task vectors.